通过监控和警报驯服 AI 野兽

AI 就像一个野兽,需要不断地喂食。它需要什么食物?当然是大数据,而且需要大量的!记住,数据和 AI 是同一枚硬币的两面。人们经常忘记 AI 模型之所以能被构建,是因为它们被喂食了数百 PB 到 EB 的数据,这些数据存储在 MinIO 企业版对象存储 上,当然,为了使这些模型有效,需要存储数千倍的数据。
但在管理如此庞大规模的数据时,不可能查看单个日志或节点来尝试理解数据。你需要的是对数据状态和整个集群基础设施的全面了解。而最常见的需要监控和更换的基础设施组件之一是硬盘驱动器 (SSD、NVMe 等)。硬盘驱动器因各种原因出现故障,MinIO 能够在即使同时出现多个驱动器故障的情况下,也能以全速运行,具体取决于 擦除码计算,并且不会出现任何问题。
但当足够多的驱动器出现故障时,物理定律就会起作用。如果这些故障驱动器没有及时更换,或者达到擦除码配置允许的最大故障驱动器数量,这可能会产生连锁反应,例如,从 Kafka 队列 读取请求的 ETL 作业可能会运行缓慢,甚至完全卡住,因为它无法从 MinIO 存储桶中读取数据,因为有太多驱动器已停止运行太长时间。
手动执行上述操作是不可能的,因此在这篇文章中,我们将向您展示如何在网络浏览器中可视化集群指标,以及如何设置警报,以便当驱动器需要更换或驱动器空间不足时,我们可以收到警报。
让我们开始吧。
先决条件
为了使这篇文章简洁明了,下面是一些我们期望您在继续执行后续步骤之前已设置的先决条件。
- 已部署并运行 MinIO 企业版。
- 在 Docker 中运行 Grafana(用于可视化)
- 在 Docker 中运行 Prometheus(用于存储指标和警报)
收集指标数据
我们将配置 Prometheus 服务从我们的 MinIO 部署中抓取和显示指标数据。除此之外,我们还将在 MinIO 指标上设置一个警报规则,以触发 AlertManager 操作。
将以下抓取配置添加到您的 Prometheus 容器中。
- 设置适当的 `scrape_interval` 值,以确保每个抓取操作在下一个抓取操作开始之前完成。建议值为 60 秒。由于要抓取的指标数量不同,一些部署需要更长的抓取间隔。为了减少 MinIO 和 Prometheus 服务器的负载,请选择最长的满足监控要求的间隔。
- 将 `job_name` 设置为与 MinIO 部署相关的值。使用唯一的值,以确保将部署指标与该 Prometheus 服务收集的任何其他指标隔离。
- 使用 MINIO_PROMETHEUS_AUTH_TYPE 设置为“public”启动的 MinIO 部署可以省略 `bearer_token` 字段。
- 对于不使用 TLS 的 MinIO 部署,将 `scheme` 设置为 `http`。
- 使用解析为 MinIO 部署的主机名设置 `targets` 数组。这可以是任何单个节点,也可以是处理连接到 MinIO 节点的负载均衡器/代理。
在 MinIO,我们建议您监控和警报以下指标。
以下查询示例返回 Prometheus 每五分钟为名为 `minio-job` 的抓取作业收集的指标
为了收到警报,让我们创建几个警报规则
以上配置将提醒您两个在 MinIO 集群中监控最为重要的方面:节点和磁盘。如果这两个指标中的任何一个低于根据 Erasure Code 设置所需的最低数量,您可能会开始看到一些数据可访问性问题。同样,物理限制在一定程度上还是起作用的。
可视化指标
要可视化指标,首先下载由 MinIO 核心工程师精心策划的 仪表板模板 链接的配置。
对于使用 服务器端加密 (SSE-KMS 或 SSE-S3)运行的 MinIO 部署,仪表板包含 KMS 的指标。这些指标包括状态、请求错误率和请求成功率。
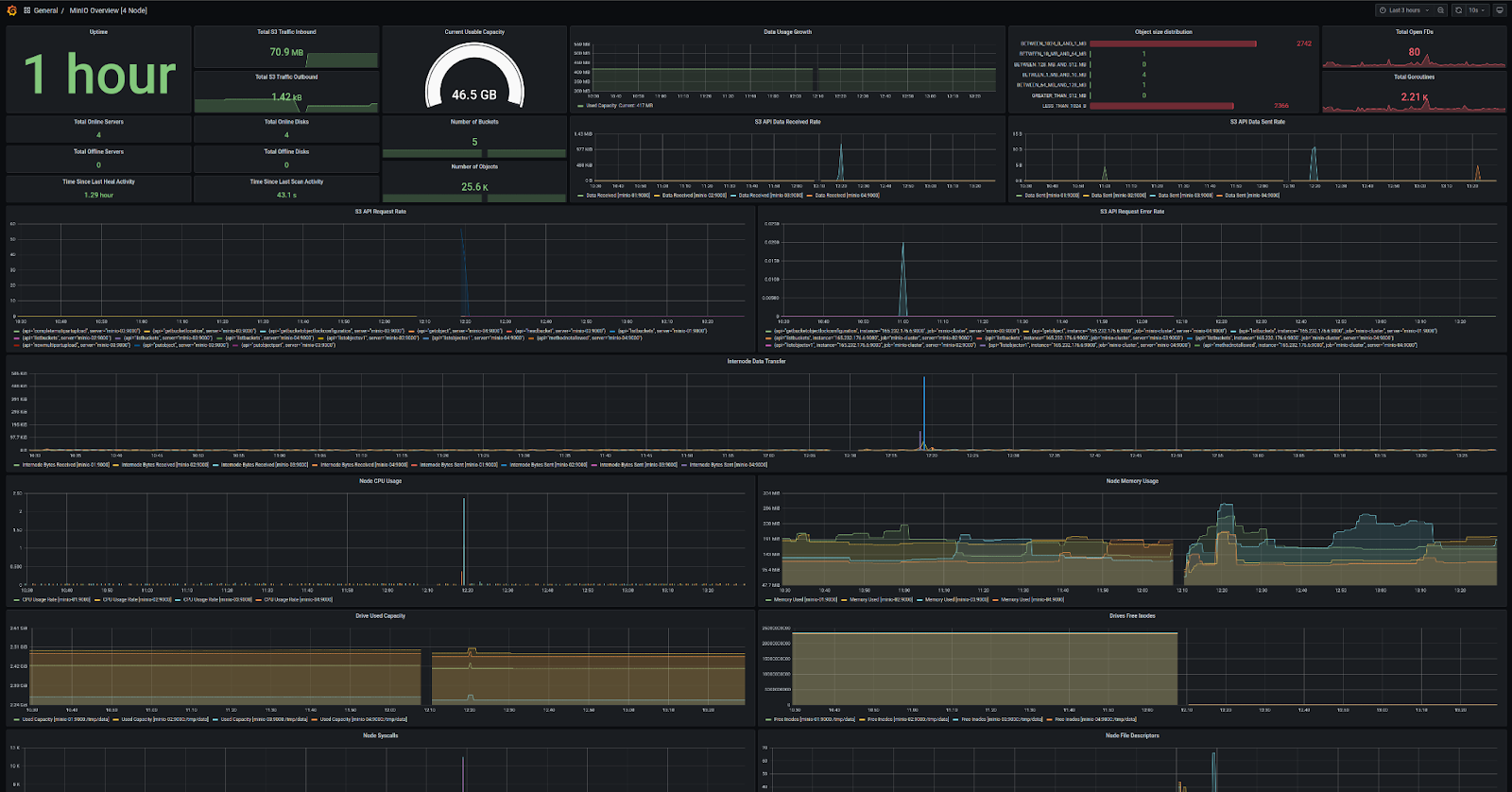
以下是如何显示存储桶指标。
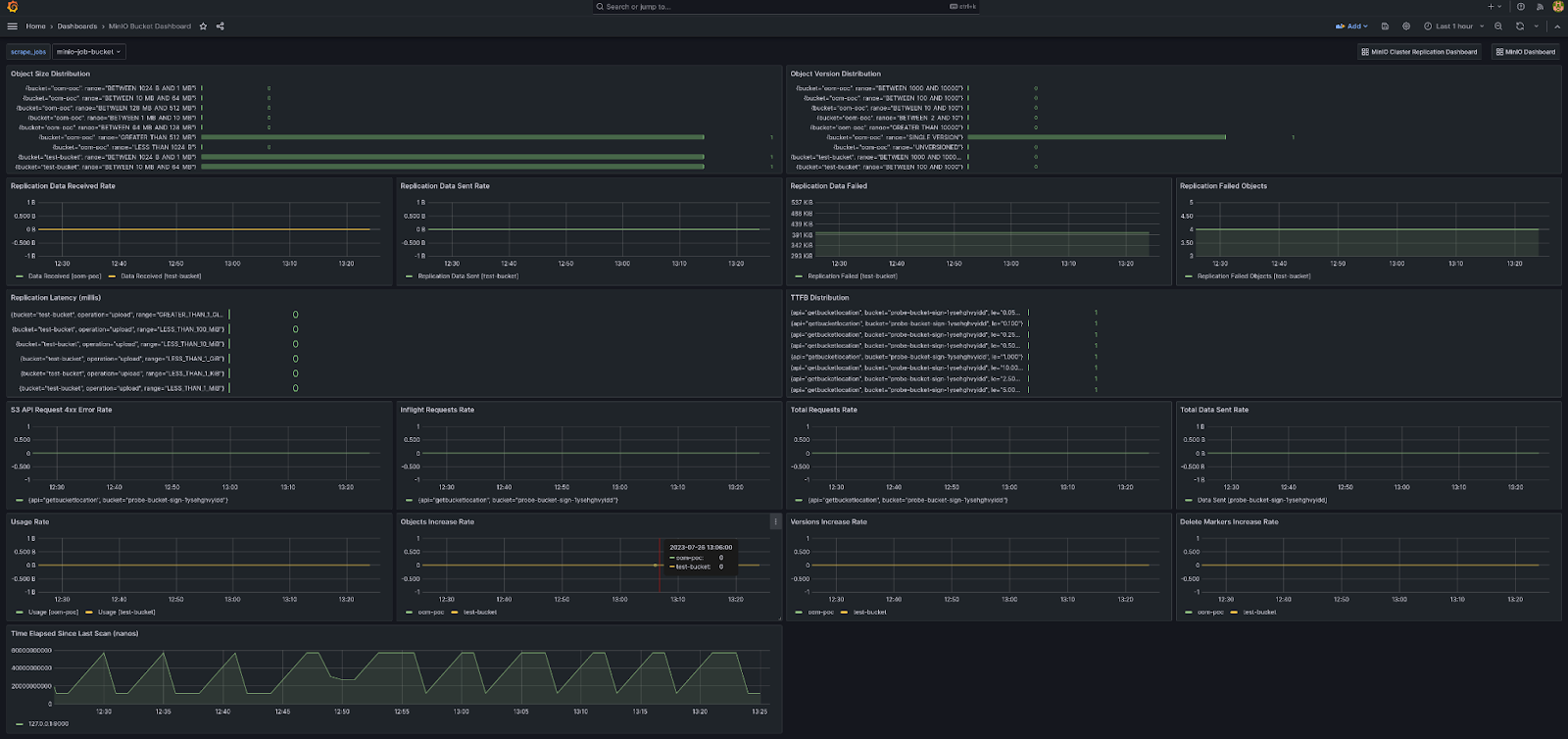
节点指标提供了更多关于每个节点的详细信息。
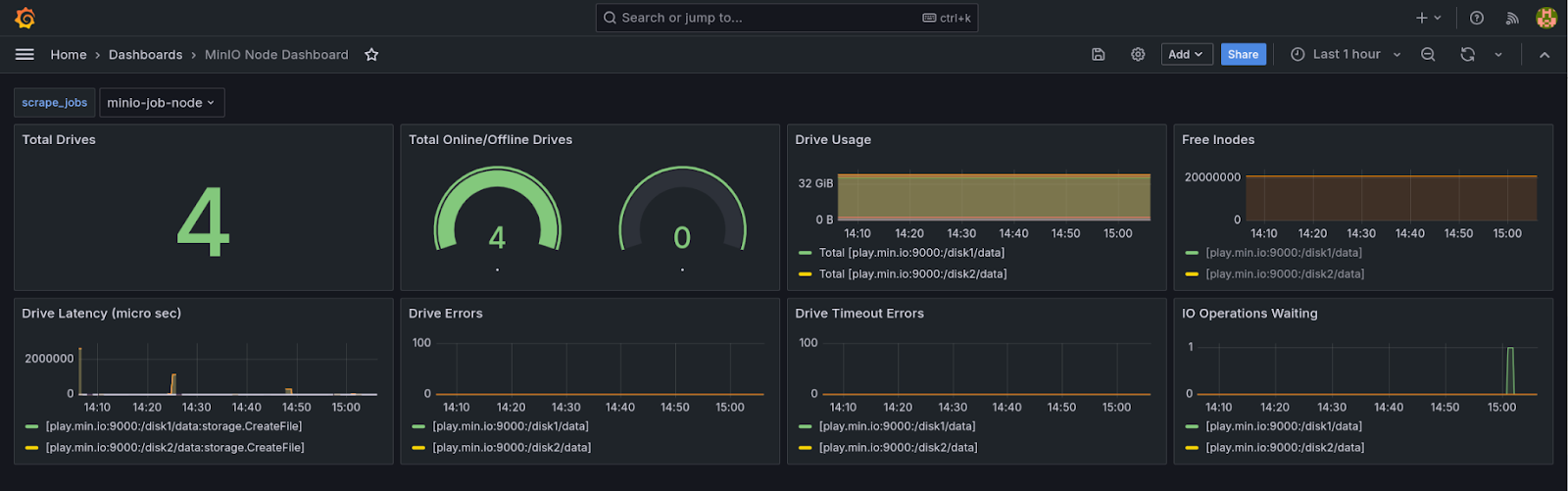
最后但并非最不重要的是复制仪表板
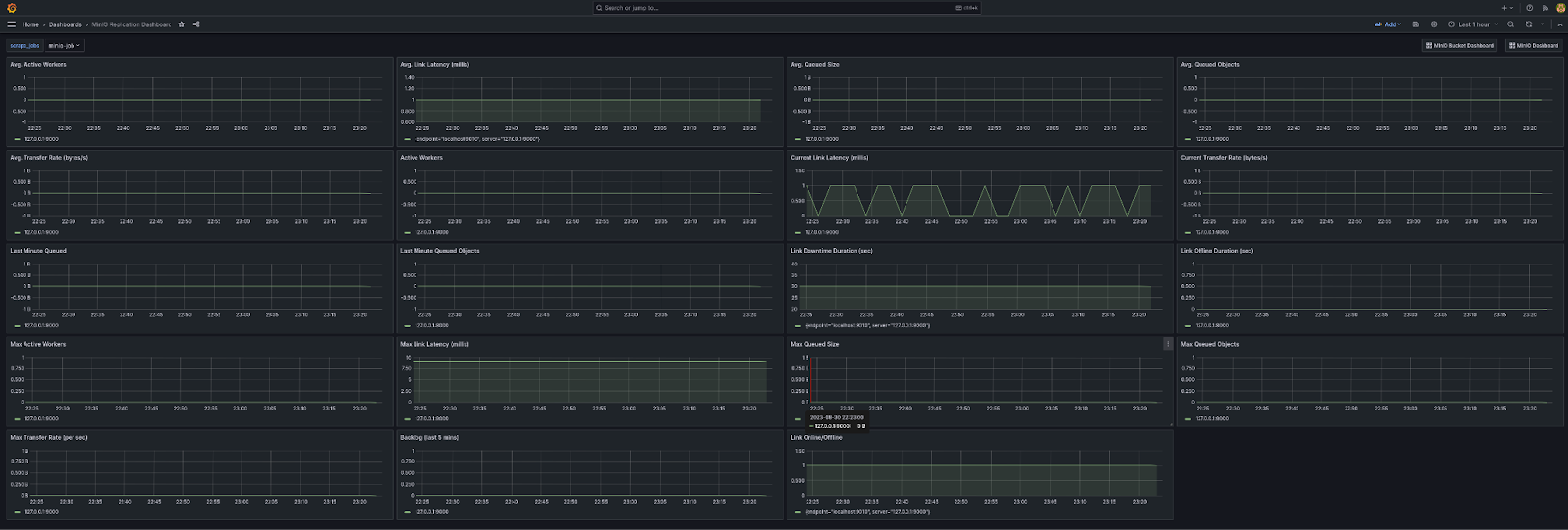
可视化您的数据以观察几个月以来的模式与监控基础设施的其他部分一样重要。
掌握您的 AI 数据基础设施
MinIO 企业版对象存储可能是最简单、最轻量级的对象存储解决方案之一。事实上,人们一次又一次地将 MinIO 的易于安装和使用评为考虑 MinIO 的三大因素之一。
虽然 MinIO 会在一定程度上(不像 Ceph)让您“自食其果”,但如果没有适当维护和监控您的基础设施,您还是只能做到一定程度。只要监控基础设施并提醒您可能出现的问题,您就可以掌握您的 AI 数据存储基础设施,确保它始终以闪电般的速度供所有人使用。
在 MinIO,我们不仅关注简洁性,还关注管理基础设施的最佳实践,这样您就不会收到凌晨 3 点的呼叫。如果您对 MinIO 企业版存储有任何疑问,或者对任何 AI/ML 或大数据主题有任何疑问,请务必在 Slack 上联系我们!