在热衷于采用 AI 的同时,有一个至关重要且常常被忽视的事实——任何 AI 项目的成功都与底层数据基础设施的质量、可靠性和性能息息相关。如果没有适当的基础,构建能力就会受到限制,从而限制所能取得的成果。
您的数据基础设施是构建整个 AI 基础设施的基石。它负责数据的收集、存储、处理和转换。使用监督学习、无监督学习和强化学习训练模型需要能够处理结构化数据(如数据仓库)的存储解决方案。另一方面,如果您正在训练大型语言模型 (LLM),则必须管理非结构化数据——原始和处理后的文档。
现代数据湖或湖仓是这两种不同类型的 AI 的基础。现代数据湖兼具数据仓库和数据湖的特点,并使用对象存储来存储所有数据。最近,我们见证了开放表格式的兴起。开放表格式 (OTF) 如 Apache Iceberg、Apache Hudi 和 Delta Lake 使对象存储能够无缝地用于数据仓库。
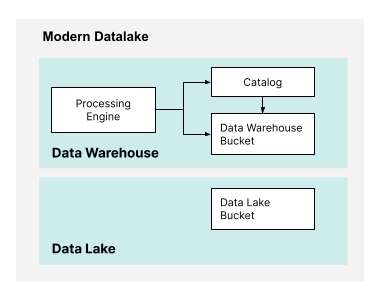
本文的其余部分将探讨如何利用现代数据湖的特性,将其与传统解决方案(如专有数据仓库和设备)区分开来。为了构建 AI 基础设施的基础,您需要以下要素:
- 计算和存储分离
- 横向扩展(而非纵向扩展)
- 软件定义
- 云原生
- 通用硬件
如果我们对上述内容达成一致,那么就会出现一系列最佳实践,这些实践侧重于性能的两个方面。如果将这些最佳实践纳入其中,现代数据湖将兼具快速和可扩展的特点。这些最佳实践包括:
计算和存储分离
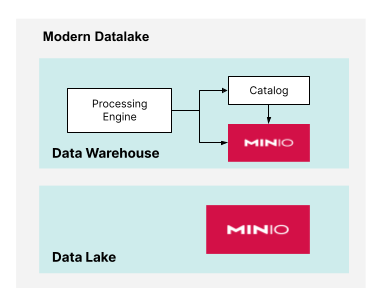
在您的数据基础设施中分离计算和存储意味着使用单独的资源进行计算和存储。这与传统的存储解决方案形成对比,在传统解决方案中,所有内容都打包在一个服务器中,或者更糟糕的是,打包在一个设备中。然而,现代数据湖将分离提升到了另一个层次。如果数据湖和数据仓库具有完全不同的存储需求,我们可以使用对象存储的两个独立实例,如下所示。
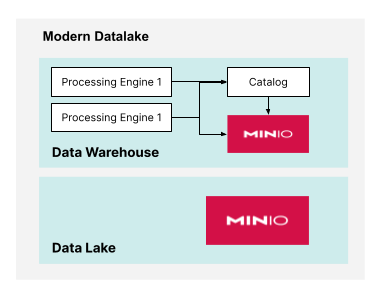
此外,如果数据仓库需要支持工作负载,而这些工作负载需要相互冲突的配置,则可以使用多个处理引擎。如下所示。
可组合基础设施允许您独立扩展计算和存储资源。这意味着您可以将更多资源分配给最需要的基础设施部分,而不是同时升级计算和存储。这使得扩展更具成本效益,因为您只需投资所需的资源。
横向扩展而非纵向扩展
AI 工作负载数据密集型,通常分布在多个 CPU 或 GPU 上,使用大量的计算能力进行训练,并且需要实时推理。横向扩展而非纵向扩展有助于优化性能并适应高速网络。
横向扩展和纵向扩展是两种不同的方法,用于提高数据基础设施的容量和性能。然而,随着 Kubernetes 等集群平台的进步以及越来越多的解决方案力求成为云原生,横向扩展正在证明是更可行的方法。在分离的基础设施中进行横向扩展可以提供:
高可用性和容错性 - 如果一个节点繁忙,另一个节点可以承担新的请求,从而减少等待时间并提高吞吐量。如果一个节点发生故障,工作负载可以转移到其他节点,从而减少停机时间并确保连续性。
性能和灵活性 - 通过将工作负载分布到多个节点或服务器上,横向扩展可以提供更好的性能,以处理更大规模的数据和更多并发请求。横向扩展也更灵活,因为您可以根据需要添加或删除节点,从而更容易适应波动的工作负载或适应季节性变化。
操作和资源效率 - 当您进行横向扩展时,维护和升级将变得更加简单。您可以对单个存储或计算节点进行维护,而不会中断整个基础设施,而不是将关键系统离线进行升级。
云原生 + 软件定义
利用现代数据湖构建强大的 AI 基础的最后一个组成部分是采用云原生和软件定义的方法。
像 Docker 这样的容器和 Kubernetes 这样的容器编排工具使得云原生架构成为可能。现代数据湖的所有组件都运行在 Kubernetes 中运行的容器中。因此,现代数据湖是云原生的。
“软件定义”指的是一种方法,在这种方法中,软件控制和管理硬件组件的配置、功能和行为,通常是在计算机系统和网络的上下文中。这是基础设施即代码运动的基石,其中重点在于智能软件和傻瓜式快速硬件。软件定义存储通过软件抽象和管理存储资源,简化了跨不同设备和存储介质分配和管理存储容量的操作。
为速度而生:NVMe 和 100GbE
要充分利用您的通用硬件和软件定义架构,您还需要两个关键部分。第一个是 NVMe 驱动器。现代面向性能的工作负载、读/写操作的随机性、小型对象数量的增加以及 SSD 价格的下降,都偏爱以 NVMe 为中心的架构。进行计算,前期成本可能较高,但总拥有成本 (TCO) 会更低。
第二个组件是 100GbE 网络。在软件定义的世界中,即使在 100GbE 下,网络也成为许多设置中的瓶颈。以下是其中一些场景:数据密集型 - AI 工作负载通常处理海量数据集,例如图像、视频、自然语言文本和传感器数据。高速网络可以快速在存储和处理单元之间传输这些大型数据集,减少数据传输瓶颈。
分布式计算 - 许多 AI 任务涉及跨多个 CPU 或 GPU 的分布式计算。高速网络能够在这些设备之间高效地进行通信和数据交换,确保计算集群能够有效地并行工作。
模型训练 - 训练深度学习模型,特别是像 Transformer 或卷积神经网络这样的 LLM,需要大量数据和计算能力。高速网络可以更快地加载数据并在分布式 GPU 之间进行同步,从而大大加快训练时间。
实时推理 - 低延迟和高吞吐量的网络对于包含 AI 的响应式应用程序至关重要。高速网络确保用户请求和模型响应之间延迟最小。
基础概念
通过坚持这些原则:计算和存储分离、横向扩展而非纵向扩展、傻瓜式快速硬件和智能云原生软件,企业可以构建一个现代数据湖,该数据湖拥有满足这些需求并推动您的 AI 项目向前发展所需的正确基础。
您不能在薄弱的基础上建造建筑物,问问古埃及人就知道了。AI 游戏的核心在于规模化的性能,这需要正确的基础。在基础设施上节省成本,就是在累积技术债务,这将导致您的积木塔在几分钟后倒塌。明智地构建,构建坚实的基础。
