使用 Apache Arrow 加速 MinIO 数据湖
 发表于 运营指南
发表于 运营指南 
越来越多的企业已经开始或已经实施了基于我们几年前完成的一些工作的数仓策略。如果您想花点时间回顾一下 - 您可以在下面找到这些帖子 这里 和 这里。
目标
在本文中,我将解释一种机制来加速使用 MinIO。就 MinIO 而言,没有任何变化,优化将针对我们数据的基础存储。我们将选择最新的格式之一来大幅提高敏捷性。我们将展示您的数据湖数据如何在系统之间传输而无需经历任何“转换”时间。
Apache Arrow
我相信理解本文需要一些关于 Spark 等应用程序如何工作的基本概念。让我用简单的术语解释一下。
想象一下,你在一个与你目前居住地不同的地点找到了一份不错的工作,并且你希望搬迁,因为新公司要求这样做并为此付费。你拥有最现代的电视、冰箱、超级柔软的皮革沙发、床等等。你聘请了一家搬家公司,他们过来,拆卸所有东西,方便地打包。他们还确保尽可能多地将物品装入集装箱,以填满卡车,以便他们可以一次性完成运输。一旦到达目的地,他们就会开箱、组装并恢复所有东西的原样。
数据也是如此。当我在 MinIO 中存储一些数据,并且我需要将其提供给另一个应用程序(例如 Spark)时,使用该应用程序需要从 MinIO 数据湖中拆卸数据、打包数据并通过网络(或无线)传输数据,接收、解包并重新组装数据。
让我们使用更多技术术语来描述这种拆卸和组装 - 数据的序列化和反序列化。不幸的是,这两个过程都很复杂且耗时。以下是一个简短的图表,说明 Apache Spark 读取数据时会发生什么情况
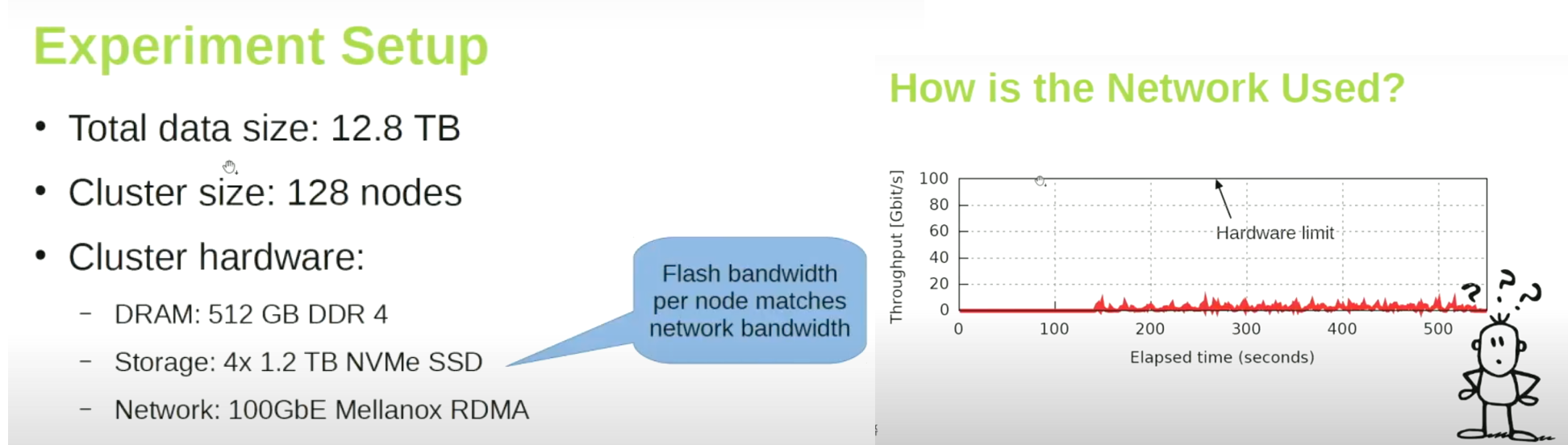
您可能以前没有注意到这个问题。假设 MinIO 位于网络上的机器上。我们编写一个 Spark Map-Reduce 应用程序。即使网络限制为 100 GbE,我们获得的速度也几乎不到 10 GbE。那么这个高速网络有什么用呢?是什么潜在的问题导致我们无法充分利用网络的潜力,或者至少无法利用 70-80% 的潜力?
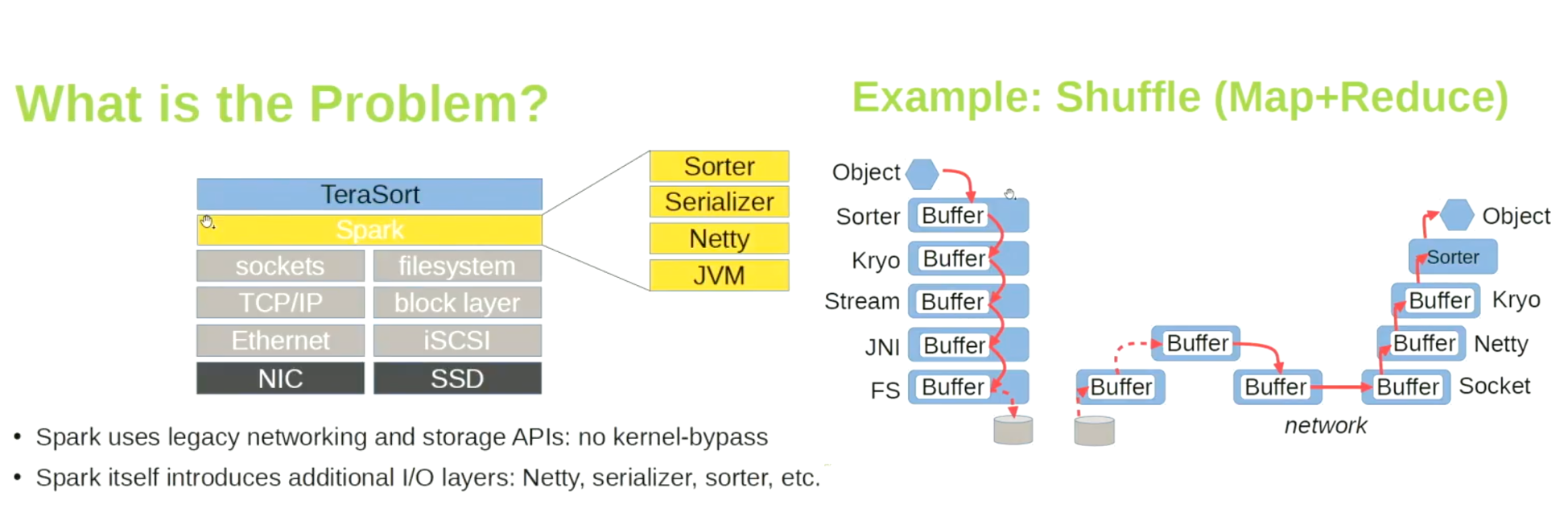
问题在于 Spark 获取数据的方式。看看数据必须经过多少层。这限制了我们可以达到的吞吐量。有一些项目,如 Apache Crail,旨在解决这些问题。
优化:列式数据格式
如果我们考虑上面提到的搬迁示例,我们会发现物流公司永远不会原封不动地搬运沙发,他们会将其拆卸以便于运输。请注意,这仅用于运输目的 - 如果目标不同,则拆卸沙发可能不是正确的方法。
鉴于数据湖的目标是分析 - 而不是事务需求,我们必须考虑这一点。对于事务,我们经常使用 Oracle 或 PostGres 等 OLTP 系统 - 因为它们特别适合这项工作。可能需要快速回顾一下 OLAP 的分析需求。
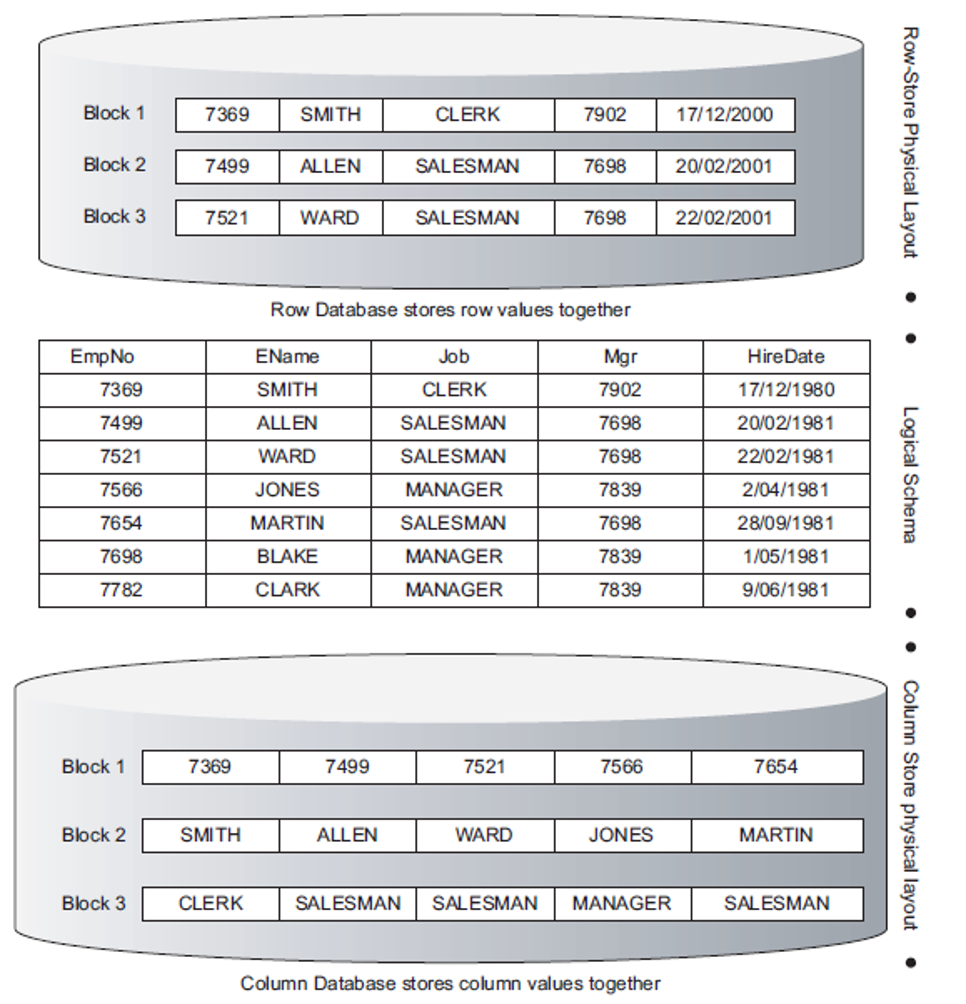
让我们从最著名的 RDMBS 表之一开始 - Oracle 的“emp”表。上半部分显示了数据如何在 RDBMS 中作为“关系”或“元组”存储。我们称之为表。我为您提供了两个查询
- select ename from emp where job = 'CLERK'
- select sum(sal) from emp
第一个是事务查询。它必须扫描表上的每一行,并在工作为文员的任何地方查找员工的姓名。第二个是分析查询 - 目标不是原子结果,而是一般结果。不幸的是,如果我们使用 RDBMS 的数据表示方式,则第一个和第二个查询都必须扫描所有行。如果数据大小为 20 GB,则或多或少都会扫描所有 20 GB。这是上图的上半部分。
让我们进行一些更改 - 获取所有列并将它们转换为行。就像矩阵的转置一样 - 并查看上图的下半部分,您的数据将是什么样子。按照此转置,整个块仅表示一列。第二个分析查询需要扫描多少个块?只有一个块,可能大小约为 2 GB。
差异很大吗?列式表示法在 ORC(优化行列式)和 Parquet 文件中使用 - 目的是使分析更快。
列式格式更容易读取,但是,它们带来了另一个问题 - 它们通常以压缩格式存储。因此,使用应用程序在读取时需要解压缩它,并在写入时将其压缩回。
请注意这一点,因为我们稍后会重新讨论这一点。
读取/写入数据的科学
让我简要解释一下软件系统中读取/写入是如何发生的以及硬件发挥了什么作用。
微处理器通常使用两种方法连接外部设备:**内存映射**或**端口映射**I/O。
内存映射 I/O 映射到与程序内存和/或用户内存相同的地址空间,并以相同的方式访问。
端口映射 I/O 使用单独的专用地址空间,并通过一组专用的微处理器指令进行访问。
在内存映射方法中,I/O 设备与 RAM 和 ROM 一起映射到系统内存映射中。要访问硬件设备,只需使用正常的内存访问指令读取或写入这些“特殊”地址即可。这种方法的优点是,每个可以访问内存的指令都可以用于操作 I/O 设备。
通常应用程序使用端口映射 I/O。如果我们对特定格式使用内存映射 I/O,它将更快,尤其是在分析需求方面。当与我们的列式数据格式结合使用时,它会变得更有优势。
欢迎来到Apache Arrow。
当您在大多数格式之间转换时,Arrow 使用内存映射 I/O 并避免序列化/反序列化开销,同时利用列式数据格式。
感谢Wes McKinney 的这项杰出创新,这个想法来自他和他的团队并不奇怪,因为他以 Python 中 Pandas 的创建者而闻名。他称 Arrow 为数据传输的未来。
以 Arrow 格式将数据存储在 MinIO 中
这就是我们将使 MinIO 变得更加强大的方式。
我们将以 Arrow 格式存储该数据,然后让使用应用程序读取它 - 从而导致速度大幅提高。第一步是将数据以 Arrow 格式放入 MinIO。在看到 Bryan Cutler 的一个更好的实现之前,我一直在使用自己的方法,他的贡献包括将 Arrow 格式集成到 Spark 中。
我们将从一个 .csv 文件开始,在本例中是从 movielens 网站下载的电影评分。为了说明目的,我大约取了 100K 行。首先,让我们编写一个 Spark 程序来读取此 CSV 文件并使用 Arrow RDD 将其写入 Arrow 格式。您可以从本文底部的链接获取完整代码。
步骤 1:build.sbt,请注意箭头依赖项
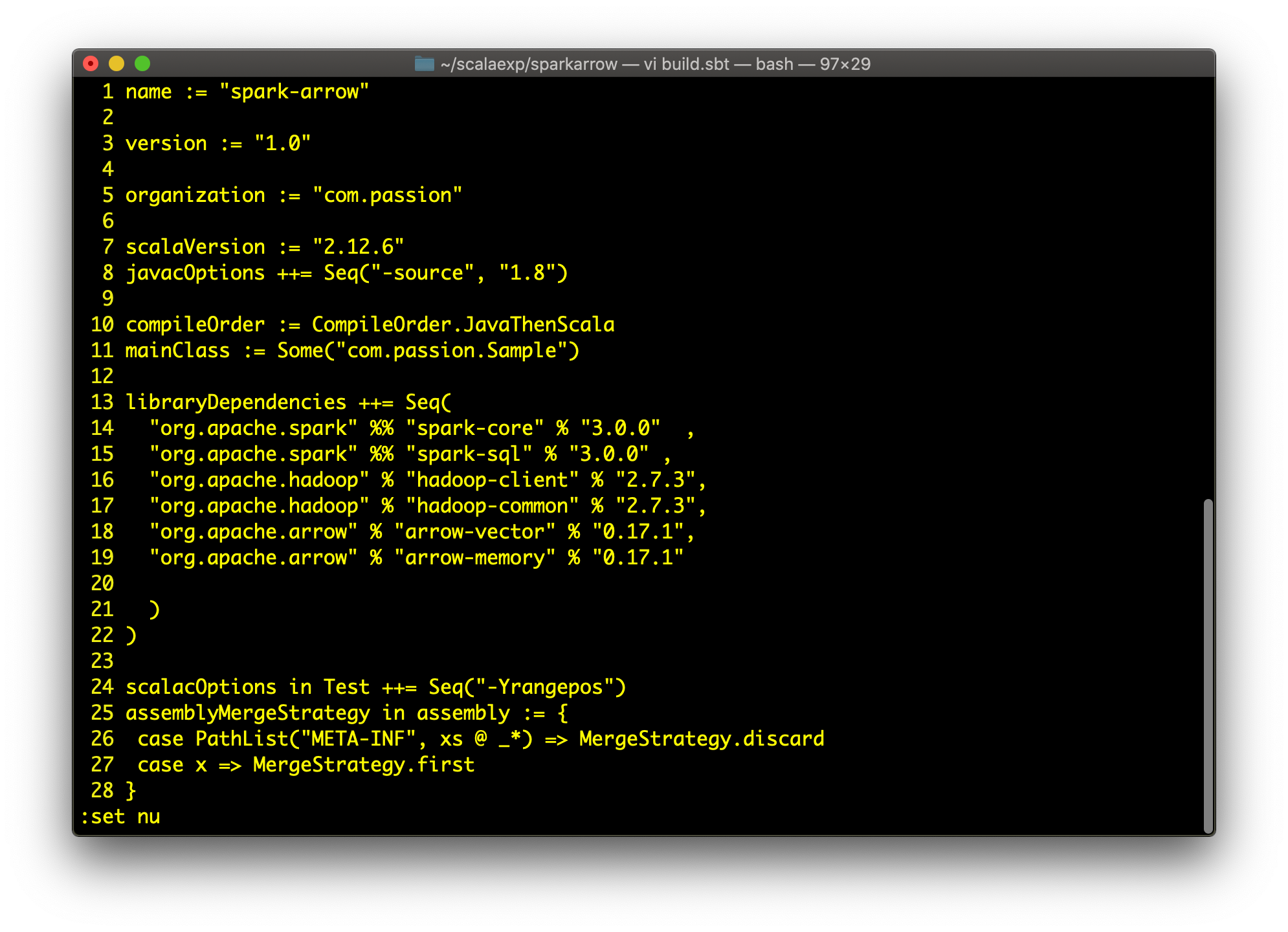
我们将使用 Spark 3.0 和 Apache Arrow 0.17.1。
ArrowRDD 类具有迭代器和 RDD 本身。为了创建自定义 RDD,您必须覆盖 mapPartitions 方法。您可以浏览代码以获取详细信息。
接下来,启动 MinIO 并创建一个名为“arrowbucket”的存储桶。

让我们使用 ArrowRDD 并创建一个本地 Arrow 文件。这是代码
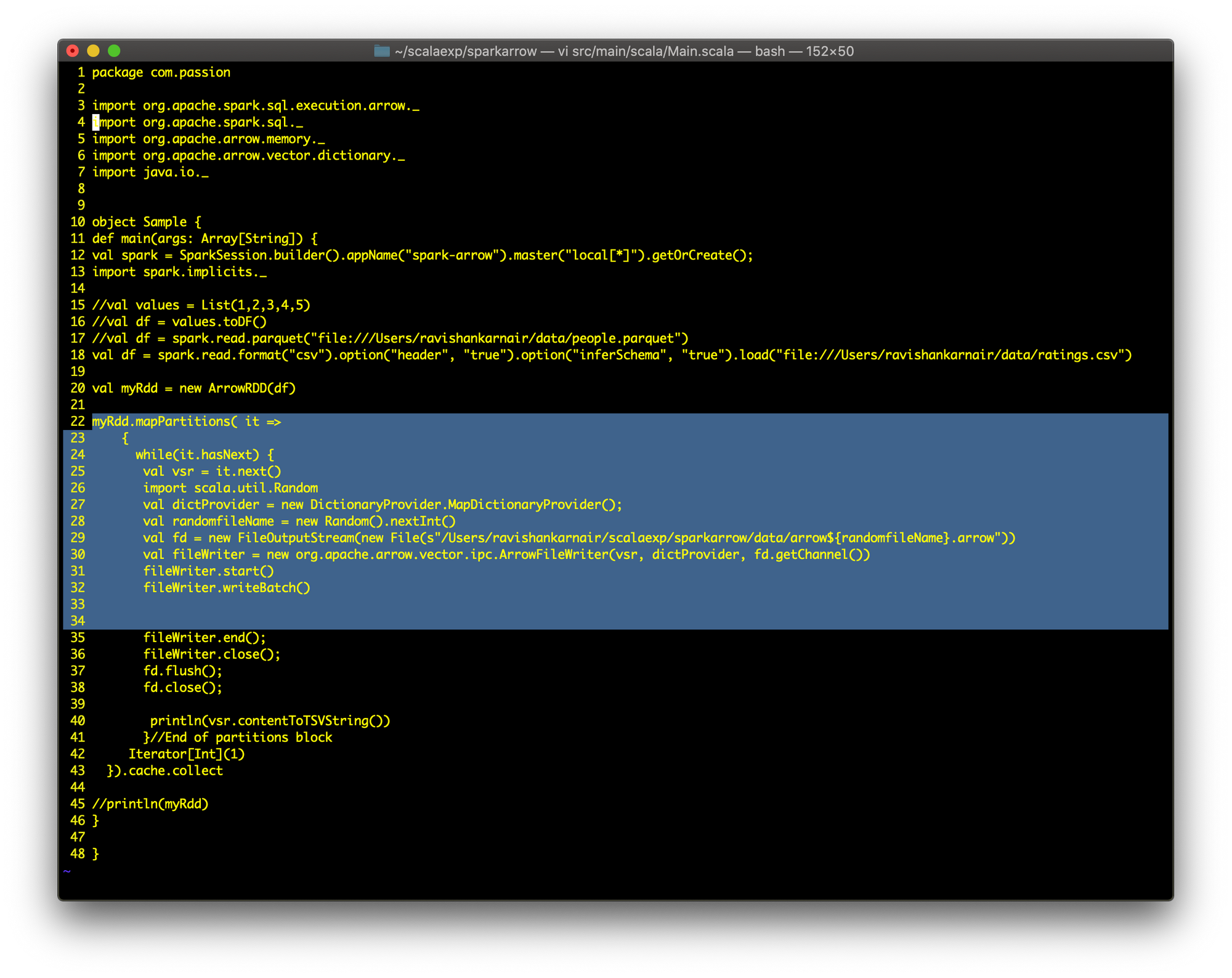
第 22 行到第 34 行执行主要部分。编译并执行代码
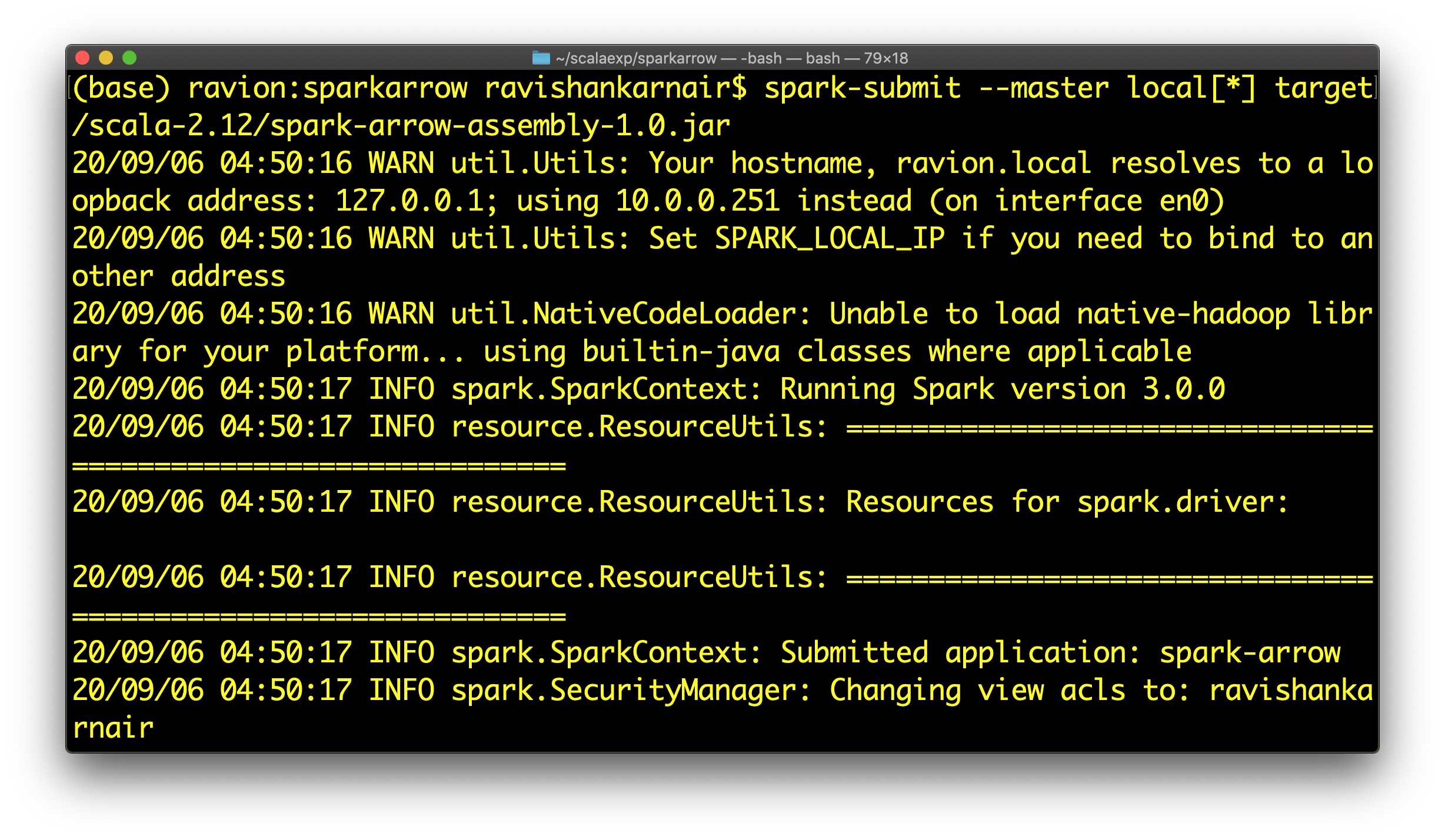
如您从代码中看到的,Arrow 格式文件生成在 data 目录中。让我们将其复制到我们之前创建的 MinIO 存储桶(存储桶名称为 arrowbucket)中
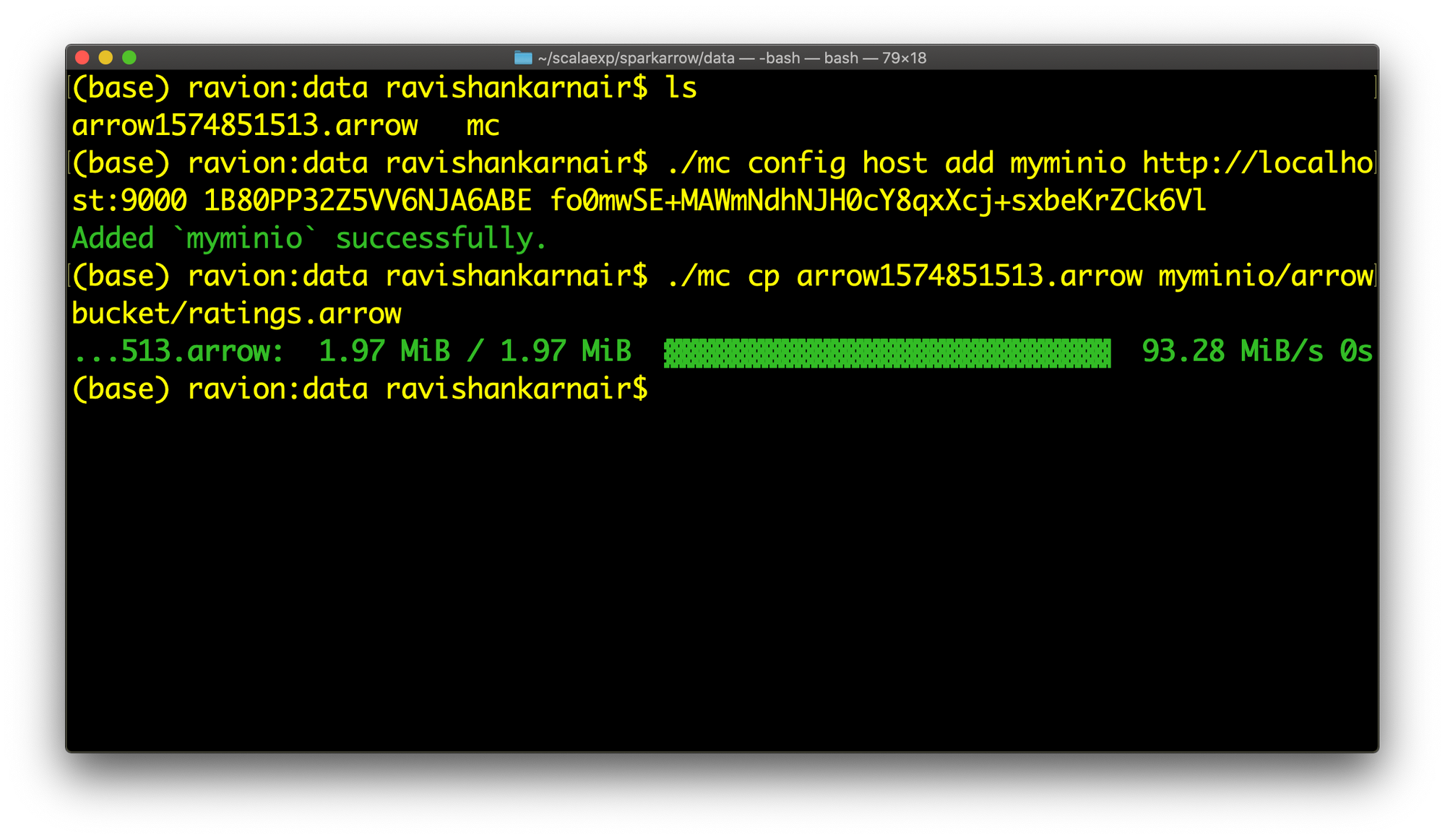
现在让我们玩得开心点。
使用您喜欢的 Python 编辑器,并编写一些代码。首先,让我们从 Spark 读取文件并将其转换为数据框开始,启用和禁用 Arrow 选项。
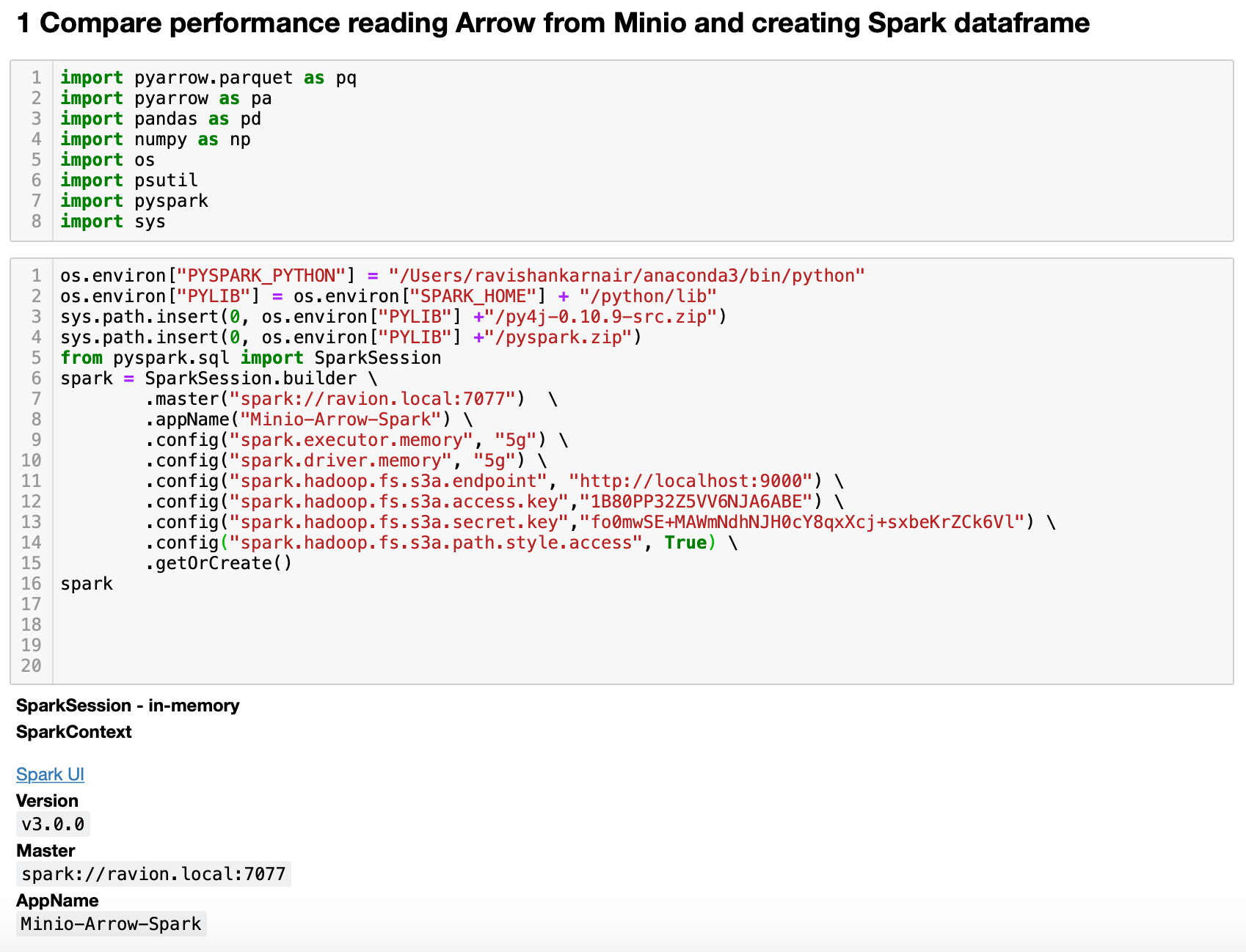
启动您的 Spark 集群。完成所有设置的代码,并检查我们是否成功创建了 Spark 上下文。为了确保我们的应用程序(第 8 行名为 Minio-Arrow-Spark)已连接,只需检查 Spark UI 即可。您应该会看到如下内容
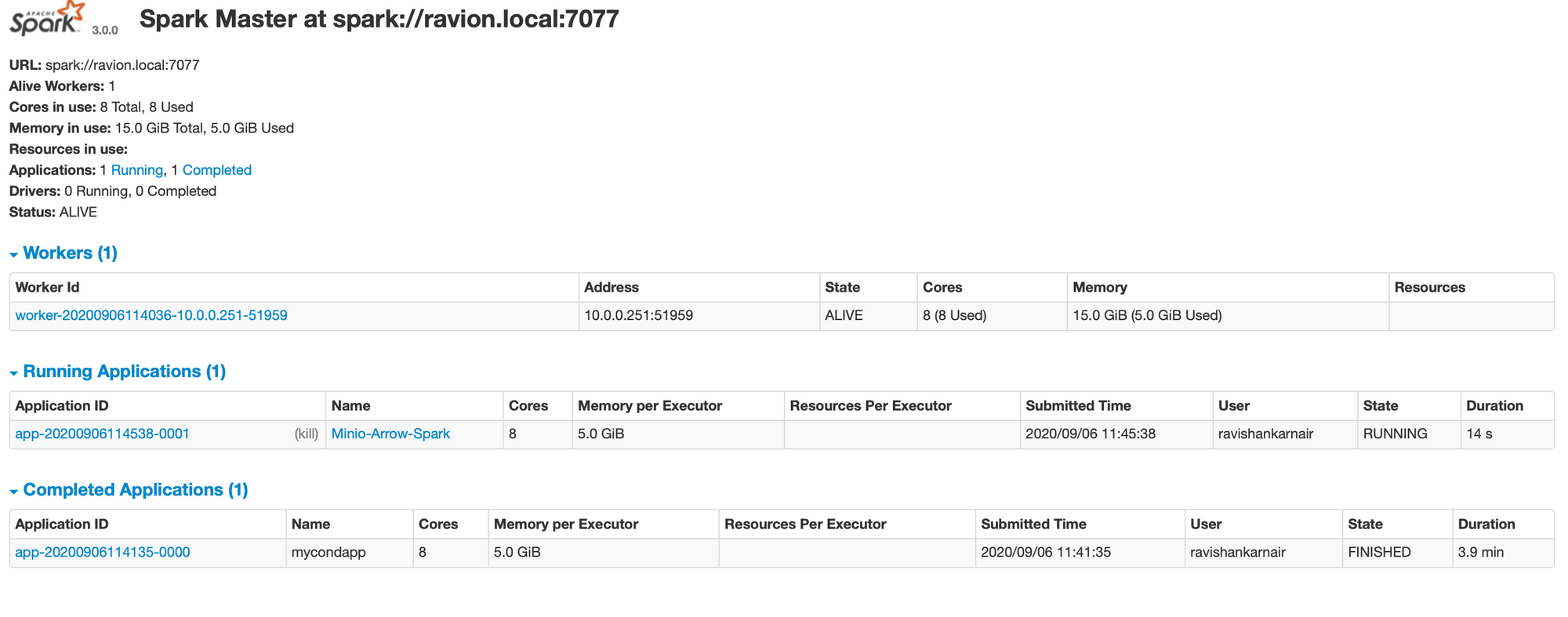
现在运行以下代码
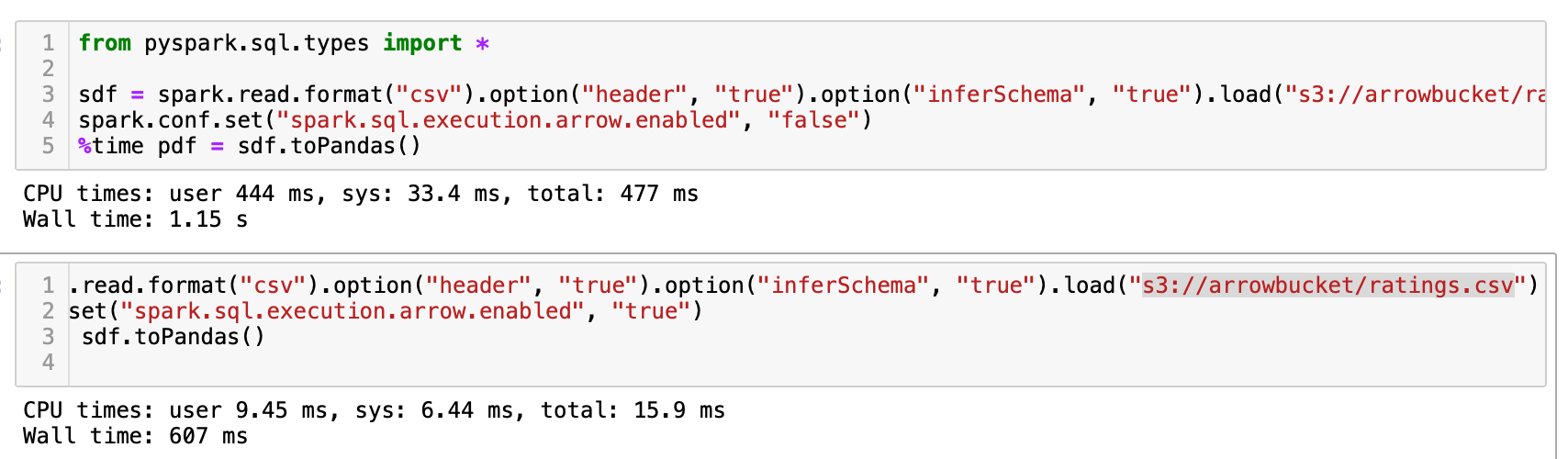
显示时间的输出表明了这种方法的强大之处。性能提升巨大,几乎达到 50%。
回想一下,我们之前创建了一个 ArrowRDD 并用它写入 MinIO。让我们测试读取它的内存消耗。我们将使用不同的方法。
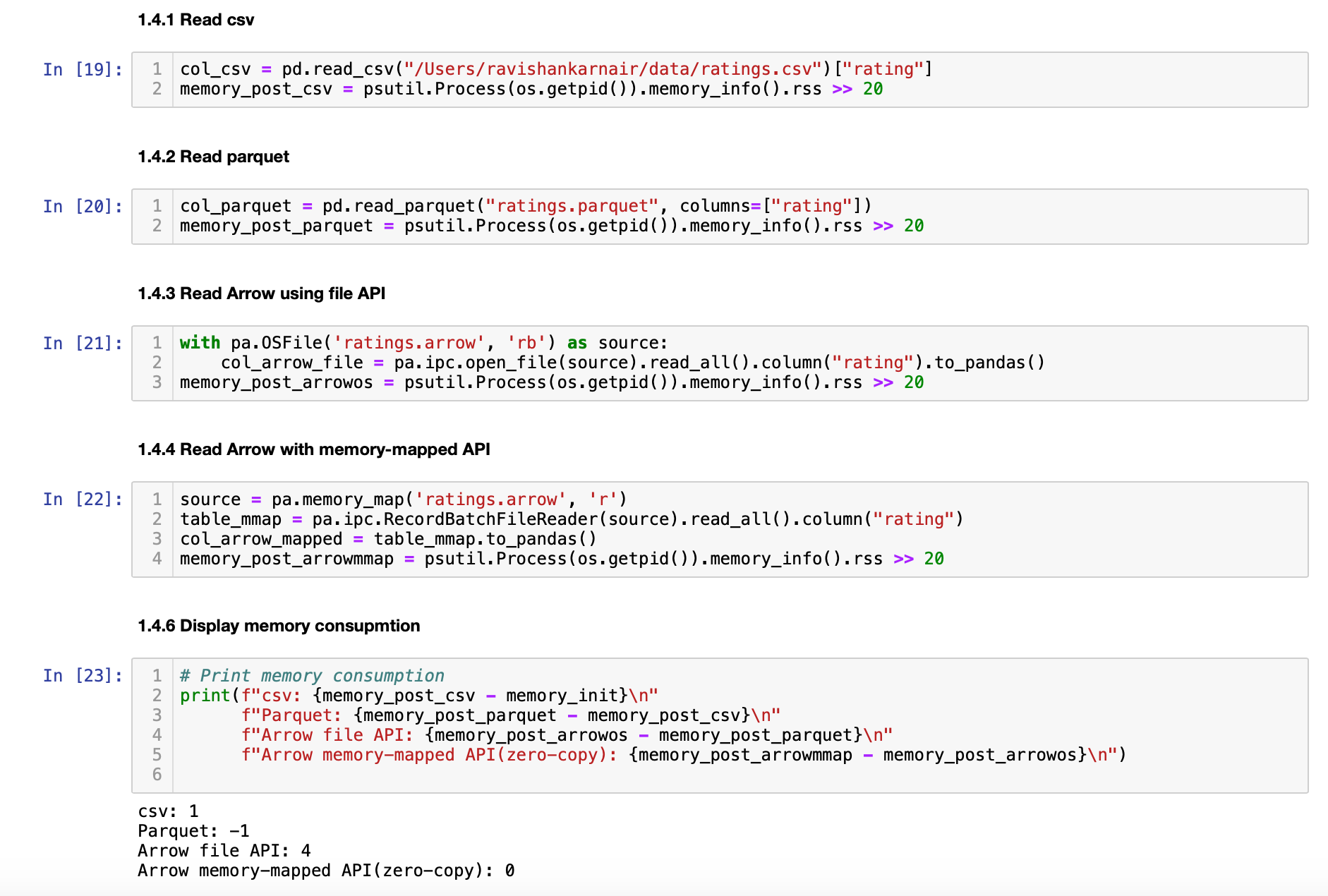
我们正在读取不同的文件格式,并查看每个格式的内存消耗。显而易见的是,基于 Arrow 格式的文件是零拷贝 - 几乎没有消耗任何内存。
通过将 MinIO 与 Arrow 格式结合,您可以增强您的分析生态系统,并几乎消除不同格式之间转换带来的摩擦。这主要是由于减少了序列化开销。
代码
您可以在此处查看 Jupyter notebook 和 ArrowRDD 代码。
关于作者
Ravishankar Nair 是一位技术布道师、顾问和鼓舞人心的演讲者。他是总部位于佛罗里达州的 PassionBytes 的 CTO。凭借其在数据工程方面的丰富专业知识,Ravi 为机器学习、现代数据湖和分布式计算技术提供咨询服务。您可以在此处查看他与 MinIO 相关的其他文章
3) 构建基于 MinIO 的本地机器学习生态系统,由 Presto、R 和 S3 Select 功能提供支持
您可以在 LinkedIn 上联系 Ravi。