揭秘数据湖:Nessie、Dremio 和 MinIO 引发波澜


我们许多人都根据后来不断变化的需求更改过数据。当我们意识到这一点时,往往已经无法回滚了。变化不仅仅是常态,更是数据管理中不可或缺的一部分,它需要一种复杂的方法。Dremio 数据目录 Nessie 提供了类似 Git 的功能来应对这一挑战。
就像 Git 已经成为软件开发的基础一样,数据工程师也需要类似的工具来并行工作、比较数据版本、将更改提升到生产环境以及在需要时回滚数据。Nessie 为数据工程师提供了一个类似 Git 的版本控制系统,用于管理数据版本、分支、合并和提交。当多个数据工程师同时处理和转换数据时,这将非常有用。Nessie 允许每个工程师在单独的分支中工作,同时以主分支的形式维护单个真相来源。此功能使数据工程团队能够在持续变化的环境中协作维护数据质量。
本文提供了一个分步指南,演示 Nessie、Dremio 和 MinIO 如何协同工作,以增强数据工程工作流中的数据质量和协作。无论您是数据工程师、机器学习工程师,还是仅仅是现代数据湖爱好者,这篇博文都将为您提供有效增强数据版本控制实践所需的知识和工具。
了解基础知识:Nessie 工作负载
Nessie 允许类似 Git 的工作负载,使您能够测试、开发和推送到生产环境。让我们分解一些关键概念
- 分支:与 Git 中一样,Nessie 中的分支允许您同时处理不同的数据工程任务。例如,您可能有一个用于特性开发、数据清理和数据转换的分支。每个分支都可以有自己的一组数据更改。
- 提交:在 Nessie 中,提交表示特定时间点的数据快照。当您对数据进行更改时,您会创建一个新的提交,该提交会记录这些更改。提交链接到特定分支。当您需要将数据恢复到稳定或已知良好的状态时,Nessie 使您可以轻松选择特定的提交并回滚到该数据版本。这确保了数据质量和一致性。
- 合并:Nessie 允许您将一个分支中的更改合并到另一个分支中。这类似于在 Git 中合并代码更改。当您合并分支时,该分支中进行的数据更改将成为目标分支的一部分。
组件
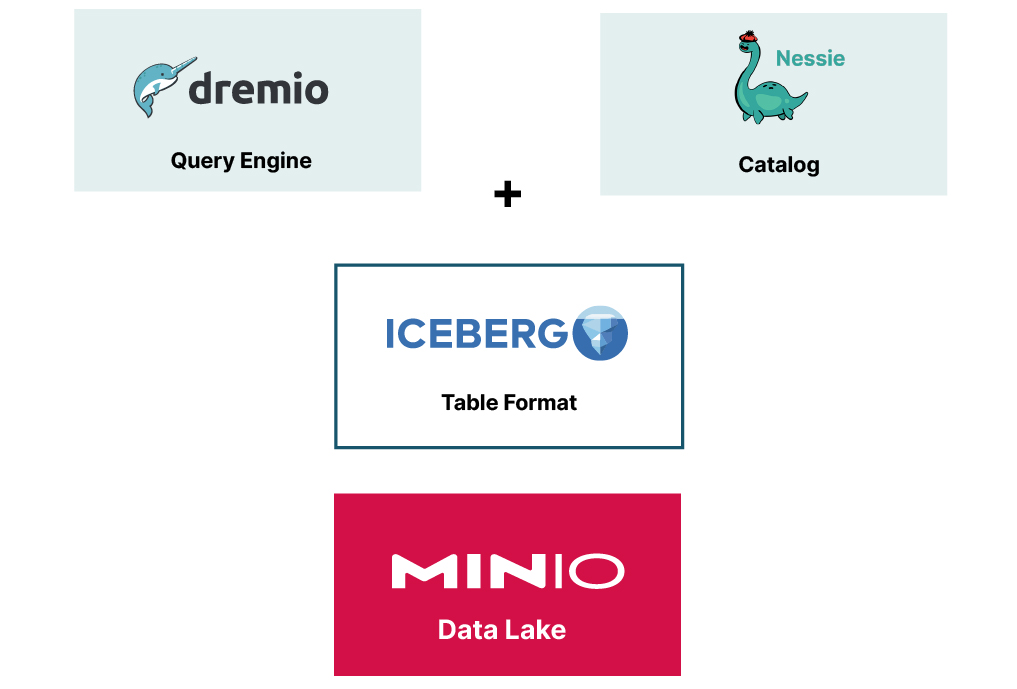
Dremio 是一款分布式分析引擎,作为开源平台运行,提供直观的自助服务界面,用于数据探索、转换和协作工作。其设计基于 Apache Arrow, 一种高速的列式内存格式。
我们已经探讨了如何使用 Kubernetes 部署 Dremio,以及如何 使用 Dremio 查询 MinIO 上的 Iceberg 表。有关 Dremio 的更多信息,请查阅 Dremio 资源。
MinIO 是高性能对象存储。MinIO 以其卓越的 速度 和 可扩展性 而闻名,是构建和维护现代数据湖基础设施的关键组成部分。MinIO 使架构师能够有效地在本地、裸机、边缘或任何公共云上管理和存储海量数据。
Apache Iceberg 是一种开放的表格式,适用于管理数据湖中的海量数据。诸如时光倒流、动态模式演变和分区演变等独特功能使其成为游戏规则的改变者,允许查询引擎安全高效地同时处理相同的数据。请参阅 使用 Iceberg 和 MinIO 构建湖仓一体架构的权威指南,以获取有关 Iceberg 功能的更多信息。
入门
本教程需要 Docker Engine 和 Docker Compose。如果您还没有安装它们,最简单的方法是安装 Docker Desktop。
本教程的这一部分基于 Dremio 的 博文。您可以从 这里 获取此项目的存储库。
首先,打开终端并导航到您克隆/下载存储库的文件夹,然后运行以下命令启动 Dremio。
docker-compose up dremio等待片刻,然后导航到 https://:9047 以访问 Dremio。更新所需字段,然后单击下一步。
接下来,运行以下命令启动 MinIO。
docker-compose up minio
以下最终的 docker-compose up 命令将启动 Nessie。
docker-compose up nessie导航到 https://:9001,使用用户名和密码 minioadmin:minioadmin 登录 MinIO。系统将提示您创建一个存储桶。
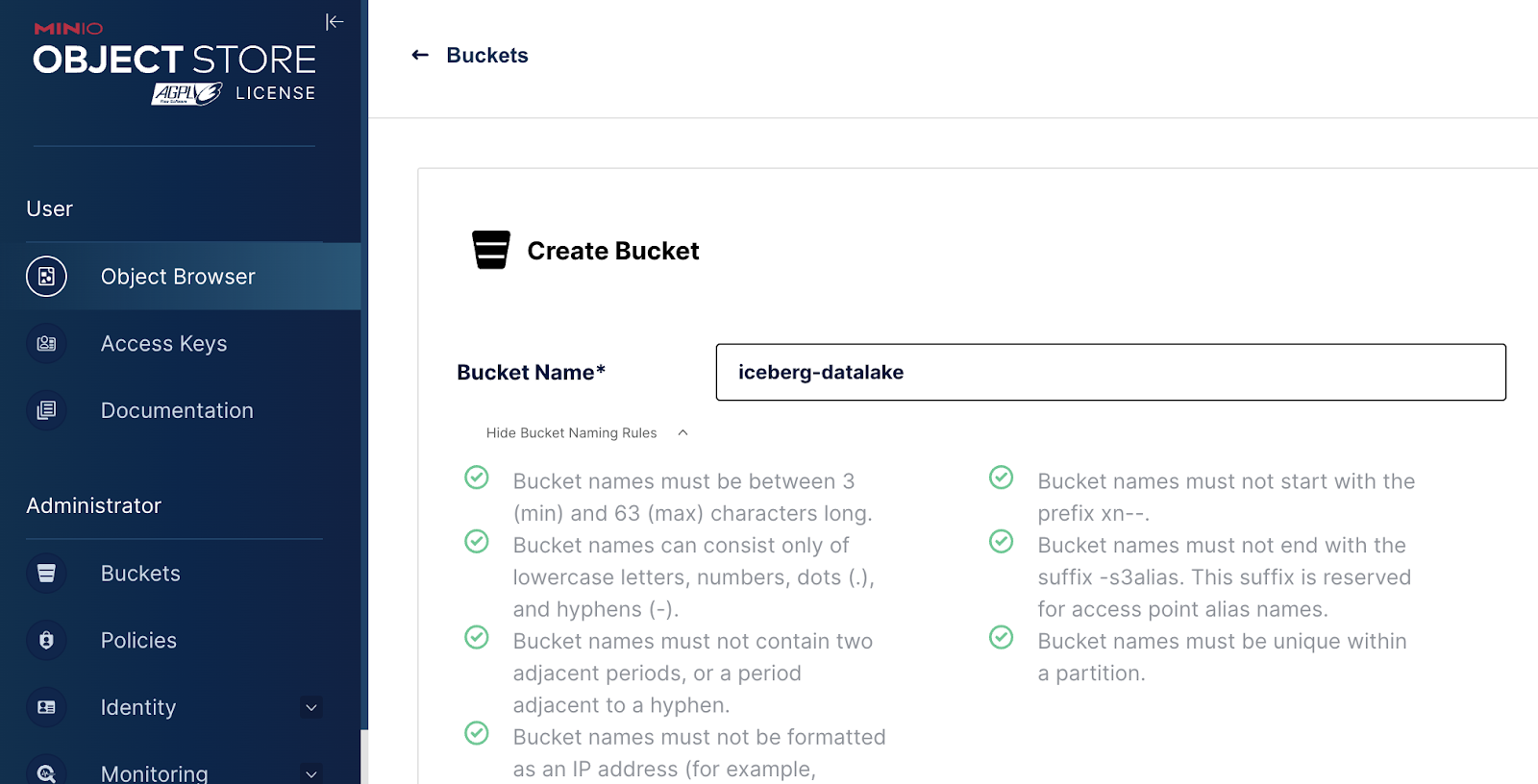
创建一个名为 iceberg-datalake 的存储桶。
然后返回到 Dremio(https://:9047),单击“添加源”并选择 Nessie。
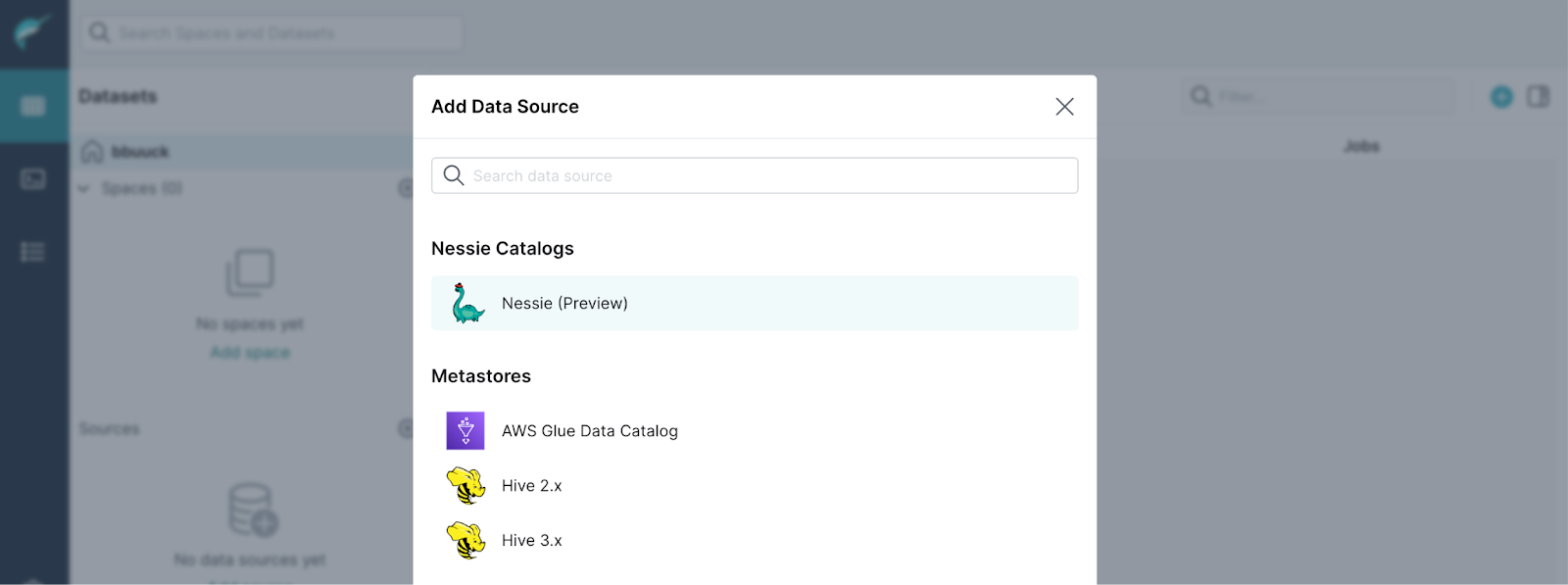
- 将名称设置为
nessie - 将端点 URL 设置为
http://nessie:19120/api/v2 - 将身份验证设置为
none
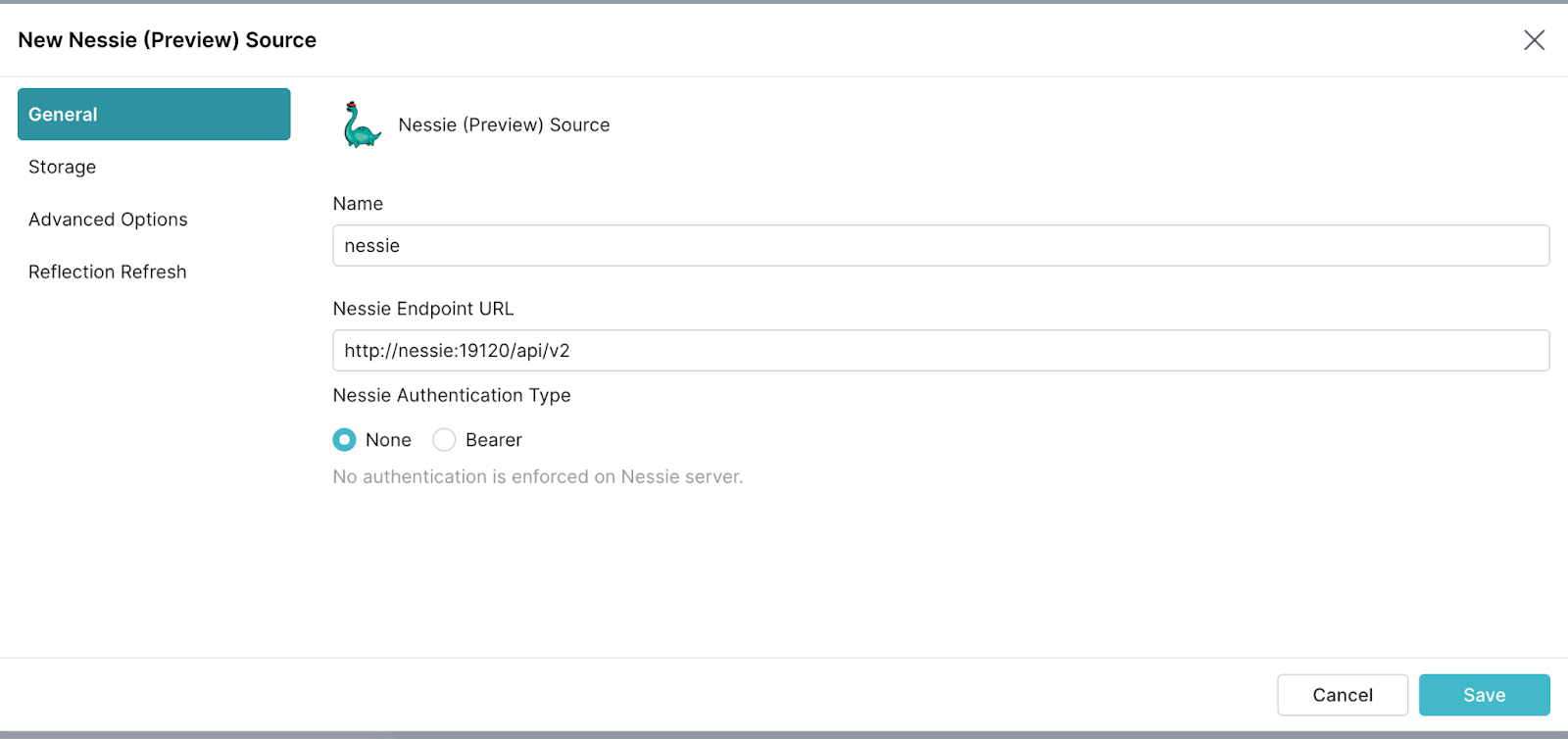
暂时不要单击“保存”。而是,在左侧的导航面板中,单击“存储”。MinIO 与 S3 API 兼容的对象存储,可以使用与 AWS S3 相同的连接路径。
- 对于您的访问密钥,设置
minioadmin - 对于您的密钥,设置
minioadmin - 将根路径设置为
/iceberg-datalake
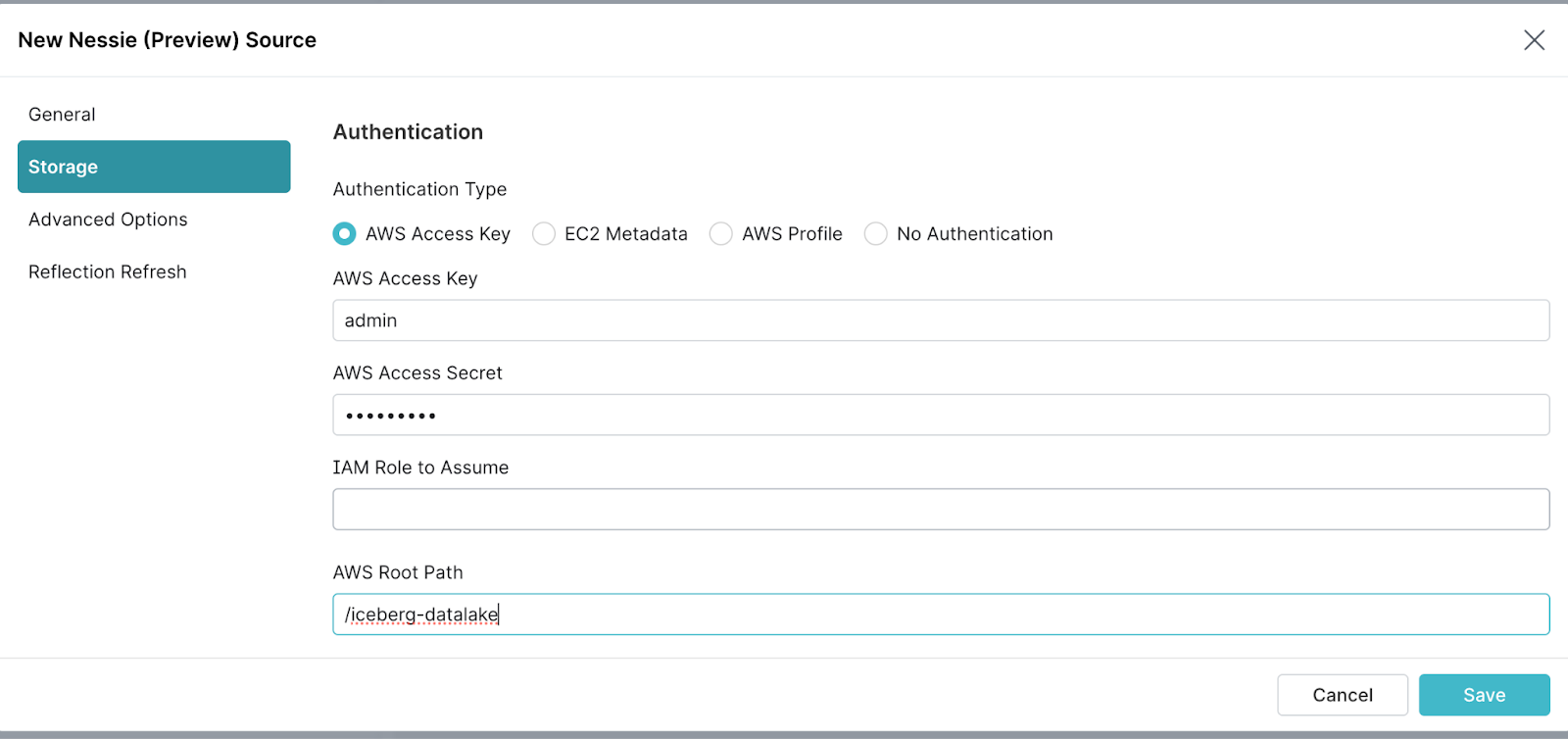
向下滚动以获取下一组说明。
- 单击“连接属性”下的“添加属性”按钮以创建和配置以下属性。
fs.s3a.path.style.access设置为truefs.s3a.endpoint设置为minio:9000dremio.s3.compat设置为true- 取消选中“加密连接”
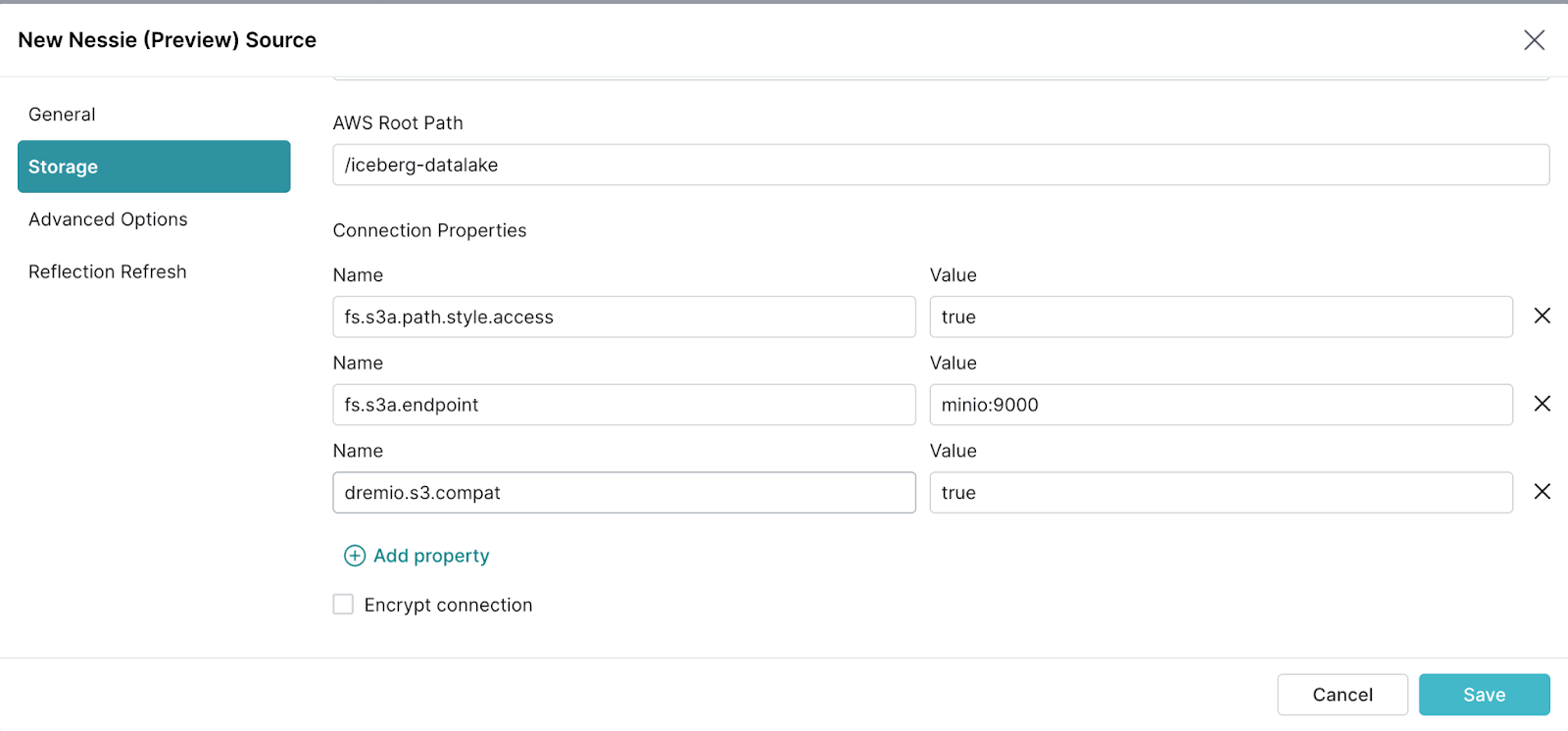
然后单击“保存”。您现在应该在数据源中看到 Nessie 目录。

创建数据源
在 Dremio 中,导航到左侧的 SQL 运行程序。确保文本编辑器右上角的“上下文”设置为我们的 Nessie 源。否则,您将必须引用上下文(如 nessie.SalesData 而不是仅 SalesData)才能运行此查询。复制并粘贴下面的 SQL 并运行。
CREATE TABLE SalesData (
id INT,
product_name VARCHAR,
sales_amount DECIMAL,
transaction_date DATE
) PARTITION BY (transaction_date);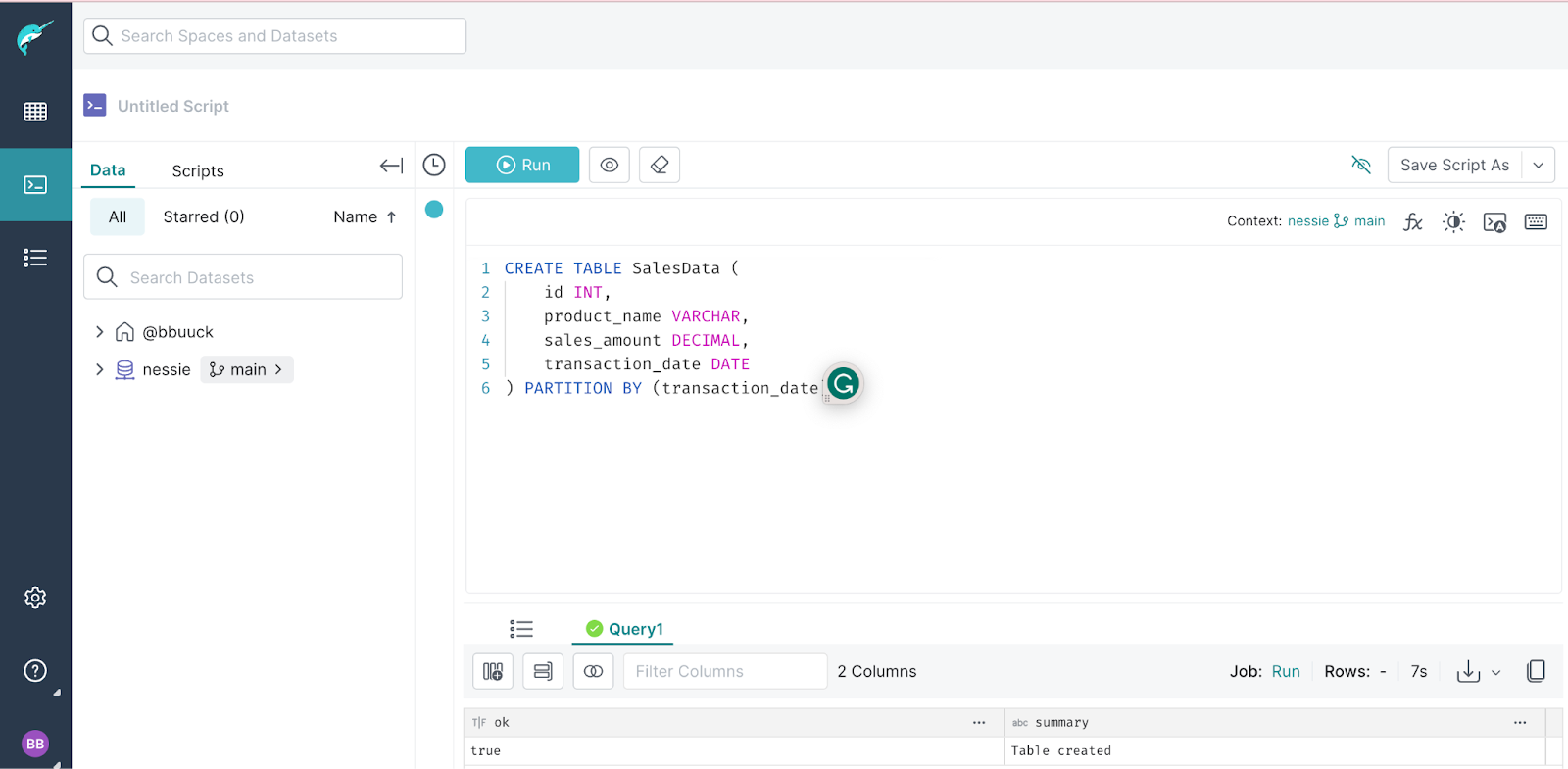
运行以下查询以将数据插入到您刚刚创建的表中。
INSERT INTO SalesData (id, product_name, sales_amount, transaction_date)
VALUES
(1, 'ProductA', 1500.00, '2023-10-15'),
(2, 'ProductB', 2000.00, '2023-10-15'),
(3, 'ProductA', 1200.00, '2023-10-16'),
(4, 'ProductC', 1800.00, '2023-10-16'),
(5, 'ProductB', 2200.00, '2023-10-17');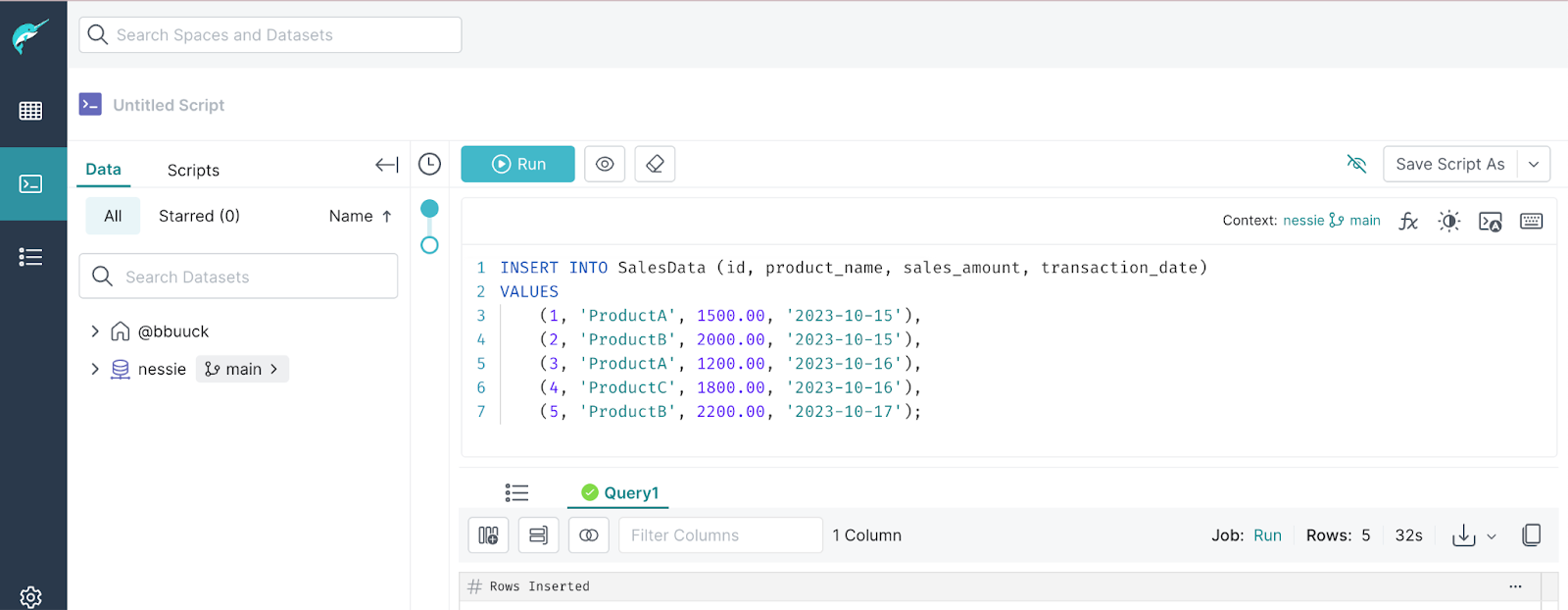
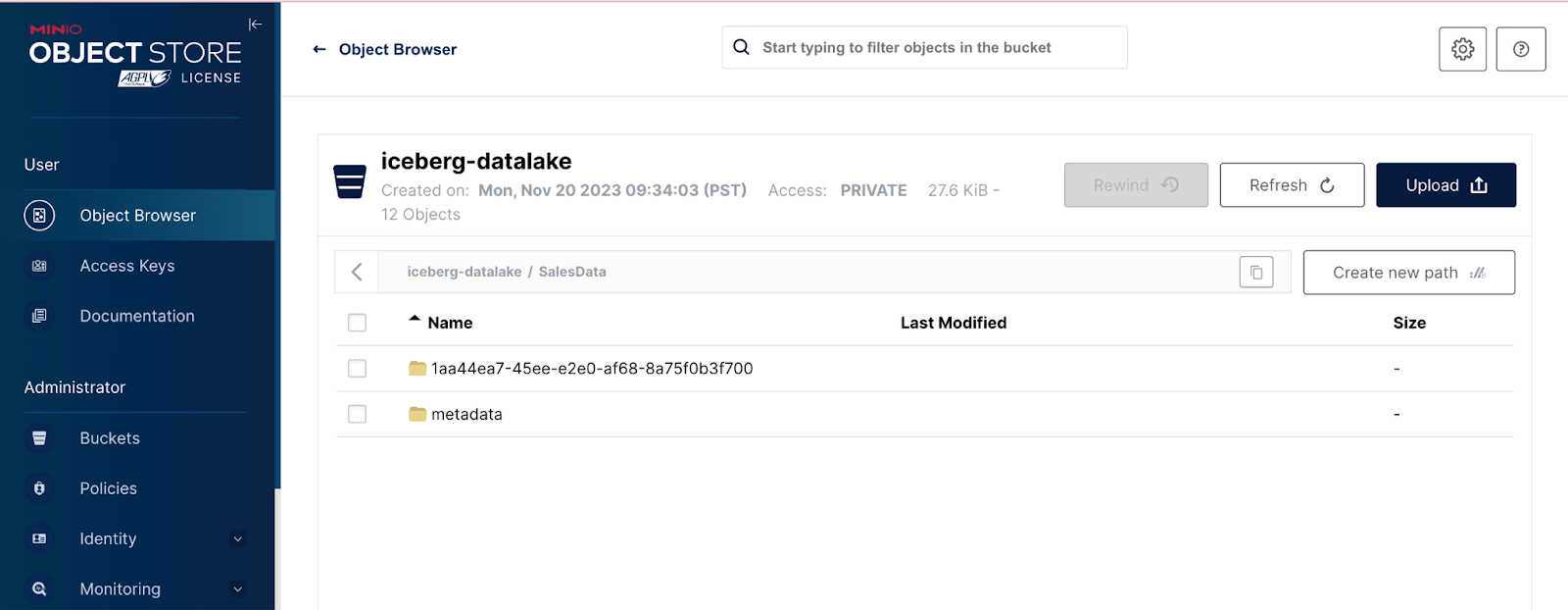
导航回 MinIO 以查看您的数据湖是否已填充了 Iceberg 表。
使用 Nessie 进行分支和合并
返回到 Dremio(https://:9047)。首先使用 AT BRANCH 语法查询主分支上的表
SELECT * FROM nessie.SalesData AT BRANCH main;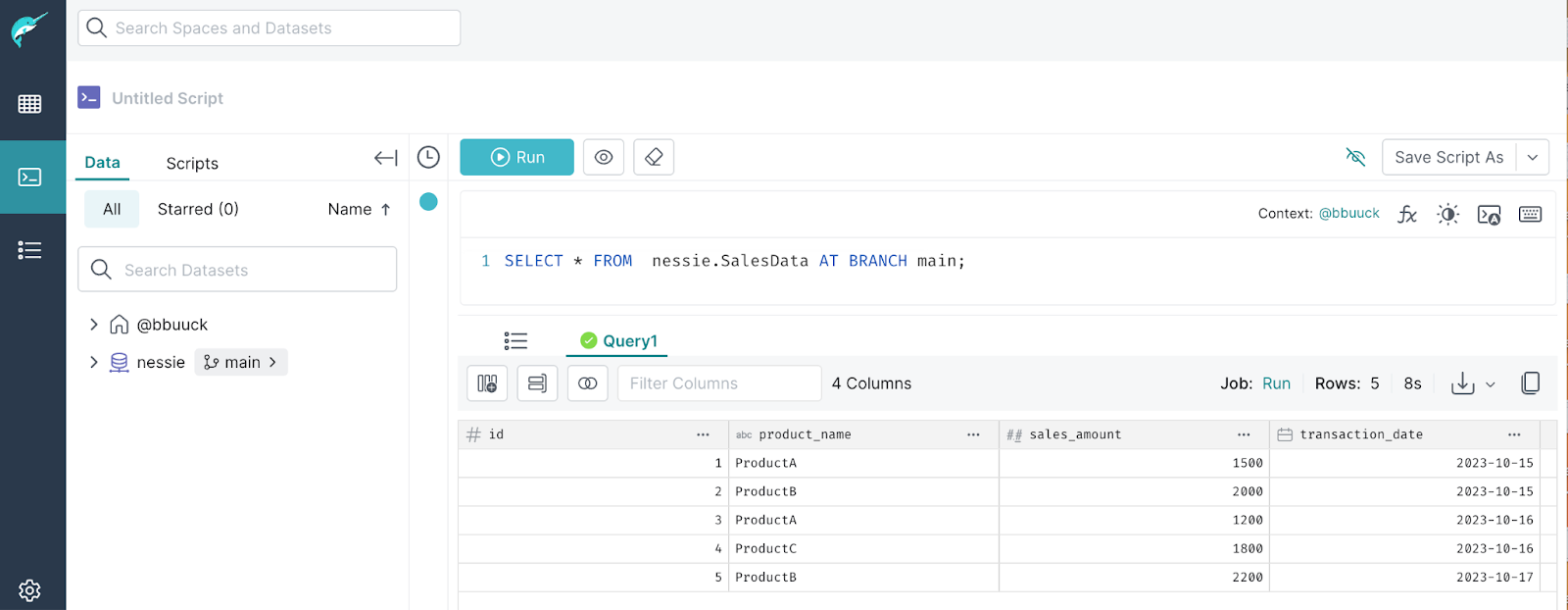
创建一个 ETL(提取、转换和加载)分支,以便您可以在不影响生产环境的情况下试用和转换数据。
CREATE BRANCH etl_06092023 in nessie在 ETL 分支中,将新数据插入表中
USE BRANCH etl_06092023 in nessie;
INSERT INTO nessie.SalesData (id, product_name, sales_amount, transaction_date) VALUES
(6, 'ProductC', 1400.00, '2023-10-18');确认 ETL 分支中新数据的即时可用性
SELECT * FROM nessie.SalesData AT BRANCH etl_06092023;注意主分支上用户更改的隔离性
SELECT * FROM nessie.SalesData AT BRANCH main;将 ETL 分支中的更改合并回主分支
MERGE BRANCH etl_06092023 INTO main in nessie;再次选择主分支以查看更改是否已合并。
SELECT * FROM nessie.SalesData AT BRANCH main这种分支策略使数据工程师能够独立处理跨多个表的众多事务。准备好后,数据工程师可以将这些事务合并到主分支中的单个、全面的多表事务中。
结论
这篇博文深入探讨了类似 Git 的版本控制在数据工程中的强大功能,重点介绍了 Nessie 如何无缝管理数据版本、分支和合并。此分步指南演示了 Nessie 如何与 Dremio 和 MinIO(作为对象存储基础)协作,以增强数据工程工作流中的数据质量和协作。
请告诉我们您的数据湖仓是什么样的,您可以发送邮件至 hello@minio.io 或加入 我们的 Slack 频道。